Introduction
In the digital era, data has emerged as one of the most valuable assets for individuals, businesses, and governments. The sheer volume, velocity, and variety of data generated from diverse sources have given rise to the concept of “Big Data.” Big Data refers to large and complex datasets that traditional data management methods struggle to handle efficiently. To manage this explosion of data, specialized technologies and approaches have been developed, conducting a new era of data management. McAfee, A. and Brynjolfsson, E. (2012) mention that the big data movement, like analytics before it, seeks to glean intelligence from data and translate that into business advantage.
In this paper, we will explore the fundamental aspects of big data technologies and data management and understand how they have transformed the way we interact with data, learned during the “Deciphering Big Data” module.
1. Big Data Technologies and Data Management:
The term “Big Data” is characterized by the three Vs: Volume, Velocity, and Variety. Volume refers to the massive amount of data being generated every second, from digital devices, social media interactions, IoT sensors, and more. Velocity refers to the high speed at which data is generated and needs to be processed to extract meaningful insights. Variety denotes the diverse types and formats of data, including structured, semi-structured, and unstructured data. Managing such large and varied datasets requires advanced tools and technologies that can efficiently capture, store, process, and analyze data. In this unit, we have gained familiarity with security data requirements. We have acquired an understanding of the issues and challenges related to managing tools and strategies in this context. Lastly, we have comprehended the skills needed for developing a data management system through a “lecture cast” and an insightful required reading.
2. Introduction to Data Types and Formats:
Data comes in various types and formats, each presenting unique challenges and opportunities for data management. Structured data follows a predefined format and is organized into rows and columns, making it easy to store in relational databases. Semi-structured data, like XML and JSON, possesses some structure but allows flexibility in the data schema. Unstructured data, on the other hand, lacks a predefined structure and includes text, images, audio, and video. Handling these diverse data types requires data management systems capable of accommodating and extracting insights from each format. During the unit two, we were able to differentiate among data formats and representations, we explored and examined data types and formats following the sections in Chapter 3 of the Kazil textbook.
Figure 1: Python code that imports XML data

3. Data Collection and Storage:
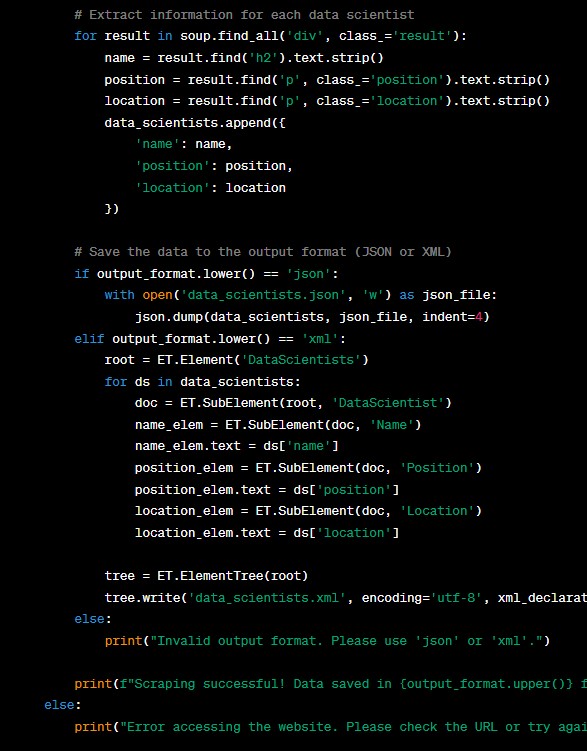
Data collection forms the foundation of the big data journey. The sources of data are vast and diverse, including social media platforms, online transactions, healthcare records, and more. In addition to traditional databases, big data storage technologies like data warehouses and data lakes have emerged to cater to the enormous volume of data. Data warehouses provide a structured environment for storing historical data, whereas data lakes store raw and unprocessed data in its native format, enabling data scientists to explore and analyze the data flexibly. Through the literature and “lecture cast” provided, we explored various sources of data, data collection methods, and we evaluated the issues and challenges that come with collection process. Furthermore, using BeautifulSoup Python library, we wrote a web scraping script using the keyword ‘Data Scientist’ and parsed the data into XML or JSON (see Figure 2).
Figure 2: Web Scraping script
Additional to that, during this week, we summarized our findings during the Collaborative Discussion 1.
4. Data Cleaning and Transformation:
Like the previous units, during this week, we reviewed the “lecture cast” and the reading provided by Essex, and we could have an introduction to concepts, techniques, and methods of data cleaning and transformation. Overall, the quality of data directly impacts the accuracy of insights gained from big data analytics. Data cleaning involves identifying and correcting errors, inconsistencies, and inaccuracies in the data. Data transformation, on the other hand, involves converting data from one format to another to facilitate better analysis. Preprocessing steps, such as outlier removal, missing value imputation, and normalization, are essential to ensure reliable and consistent results.
5. Automating Data Collection:
The reading during that week centred on data cleaning and transformation with an emphasis on data scraping, pre-processing, data imputation and handling of outliers and automation and, and we continued with the Data Cleaning activities in Lecture Cast (Unit 4). In conclusion, the volume and velocity of data make manual data collection and entry impractical. Automation plays a significant role in streamlining data collection processes. Extract, Transform, Load (ETL) pipelines are commonly used to automate the process of extracting data from various sources, transforming it into a consistent format, and loading it into a data warehouse or data lake. Automation not only improves efficiency but also reduces the likelihood of human errors in the data collection process.
6. Database Design and Normalization:
“Lecture cast” and reading of that unit helped me to understand that design is a crucial aspect of data management. An efficient database design ensures data is organized logically, reduces data redundancy, and enhances data integrity. Normalization is a key technique used in relational database design to eliminate data anomalies and ensure that data is stored in a structured and efficient manner. Proper database design and normalization lead to better performance and easier maintenance of the data.
7. Constructing Normalised Tables and Database Build
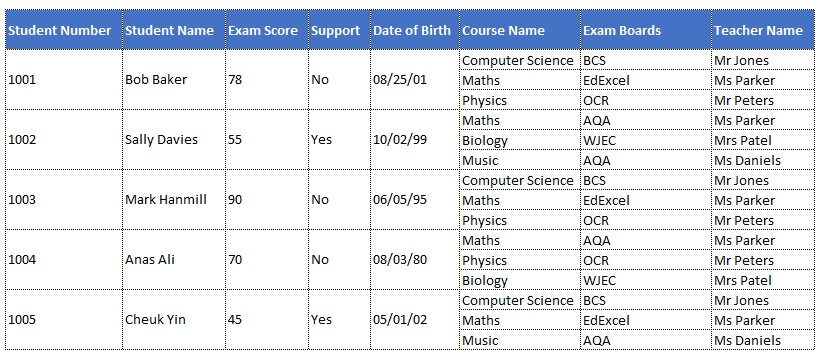
Normalization reduces redundancy, ensures data integrity, and facilitates streamlined query processing. It divides data into smaller, manageable units, following normalization rules like 1NF, 2NF, and 3NF. This organization minimizes duplication and avoids anomalies. A well-structured database enhances data retrieval, scalability, and maintainability while optimizing performance. However, striking a balance between normalization and denormalization is essential to prevent over-complexity. Ultimately, normalized tables lay the foundation for reliable, adaptable, and efficient data-driven applications. Throughout this unit, we completed a normalization and data-built tasks (see Figure 3)
Figure 3: Input for normalization task
8. Compliance and Regulatory Framework for Managing Data:
In that unit, we examined compliance frameworks with regards to data management in respect of rights of individuals and obligations of organisation to stakeholders. In summary, with the increasing reliance on data, data privacy and security have become significant concerns. Governments and regulatory bodies have enacted laws to protect individuals’ data privacy and ensure ethical data management practices. One of the most notable regulations is the General Data Protection Regulation (GDPR) in the European Union, which aims to safeguard the privacy and rights of individuals in the digital age. Additionally, organizations must adhere to industry-specific compliance requirements when handling sensitive data, such as healthcare or financial data.
9. Database Management Systems (DBMS) and Models:
“Lecture cast” and reading helped me to concluded that a Database Management System (DBMS) is a software system that enables the storage, retrieval, and manipulation of data in a database. Different types of DBMS exist to cater to varying data management needs. Relational databases, based on the relational model, use tables and key relationships to store and manage data. NoSQL databases, on the other hand, offer greater flexibility and scalability for handling unstructured and semi-structured data. NewSQL databases combine the best of both worlds, offering the advantages of both relational and NoSQL databases.
10. APIs (Application Programming Interfaces) for Data Parsing:
At the end of this week, we summarized our findings in the Collaborative Discussion 2 that happened during the last 3 weeks and, it was about the differences between GDPR and the data privacy laws within our countries of residence. Additional to that, we analysed and evaluated APIs (Application Programming Interface). APIs play a crucial role in data parsing and integration, allowing applications to interact and communicate with each other seamlessly. They provide a standardized way for applications to request and exchange data, enabling data-driven functionalities and interoperability between different systems. APIs have become integral in enabling data-driven applications and services that leverage big data.
11. DBMS Transaction and Recovery:
In that unit, we looked at how database systems can fail and what systems are in place to guarantee system failures do not lose data or interfere with the integrity of the data within the system, we looked at achieving a database in a “consistent state” where transactions are either fully committed or do not commit at all, alleviating errors within the database. Overall, in a multi-user database environment, concurrent transactions may occur simultaneously, potentially leading to data inconsistencies. DBMS ensures data integrity through the concept of transactions, which group related operations into a single logical unit. If a transaction fails due to errors or system crashes, DBMS provides recovery mechanisms to bring the database back to a consistent state.
12. The Future of Big Data Analytics:
During the last week, we explored the role of machine learning and how that would drive the advances of big data analysis and found that as technology advances, the future of big data analytics holds numerous exciting possibilities. Machine learning and artificial intelligence are expected to play a more significant role in automating data analysis and extracting insights from vast datasets. Additionally, the development of quantum computing could revolutionize big data processing and lead to even more powerful data management and analysis capabilities.
Conclusion
Big Data Technologies have brought about a paradigm shift in the way we manage and analyze data. From data collection to storage, cleaning, and analysis, each step in the data management process is crucial for extracting meaningful insights. Organizations that effectively harness Big Data’s potential will gain a competitive advantage, making data-driven decision-making an indispensable aspect of various industries. As we look to the future, the ongoing advancements in Big Data Analytics will shape the way we interact with data, propelling us into an era of unparalleled innovation and transformative discoveries.
Individual Reflection
The duration of this module has been a transformative voyage for me, delving into the complexities of data wrangling through the exploration of data extraction, exploration, cleaning, and modelling techniques using Python and SQL. This essay showcases my development through artifacts, including discussions, wiki submissions, team meeting notes, and peer and tutor feedback. Additionally, I will explain my individual contributions to the projects, evaluate the final project compared to the initial proposal, and provide insights into the impact of this experience on both my professional and personal development.
The “Deciphering Big Data” module provided a comprehensive overview of various data processing techniques, leading to a deeper understanding of working with data. I discovered the significance of data extraction, which involves acquiring data from various sources, such as web scraping and API integration. I realized that data cleaning was a crucial step, as messy data could significantly impact the results of any analysis. Understanding the importance of data integrity, I learned how to identify and manage missing values, outliers, and inconsistencies to ensure reliable results.
As a member of a team during this module, I had the opportunity to collaborate with my peers on a project. In addition, the complexities arising from diverse backgrounds, nationalities, and time zones necessitate a mindful approach to team management. By acknowledging the challenges and capitalizing on the advantages, we leveraged the power of our differences in business, IT, and analytics. My strengths in data analysis proved to be particularly beneficial during the exploratory phase. Furthermore, we conducted work sessions at least twice a week, where we all actively supported the project, and I actively participated in brainstorming sessions, contributed to the formulation of project ideas, and engaged in meaningful discussions to refine our approaches. By fostering a collaborative and supportive team environment, I aimed to encourage diverse perspectives and ensure everyone’s ideas were valued.
As we decided to develop a database system for a recruitment consulting firm based in the UK, I took the initiative to create the first draft of the DBMS (see Figure 4 and Fifure 5). Our proposed database design for the recruitment system reflects a comprehensive approach to optimize the client’s talent acquisition process. The logical design encompasses critical data entities and attributes, facilitating seamless management of candidate profiles, job openings, companies, and recruiters. The data management pipeline and data cleaning techniques ensure data reliability and accuracy throughout the recruitment process.
Figure 4: DBMS Recruitment System Design
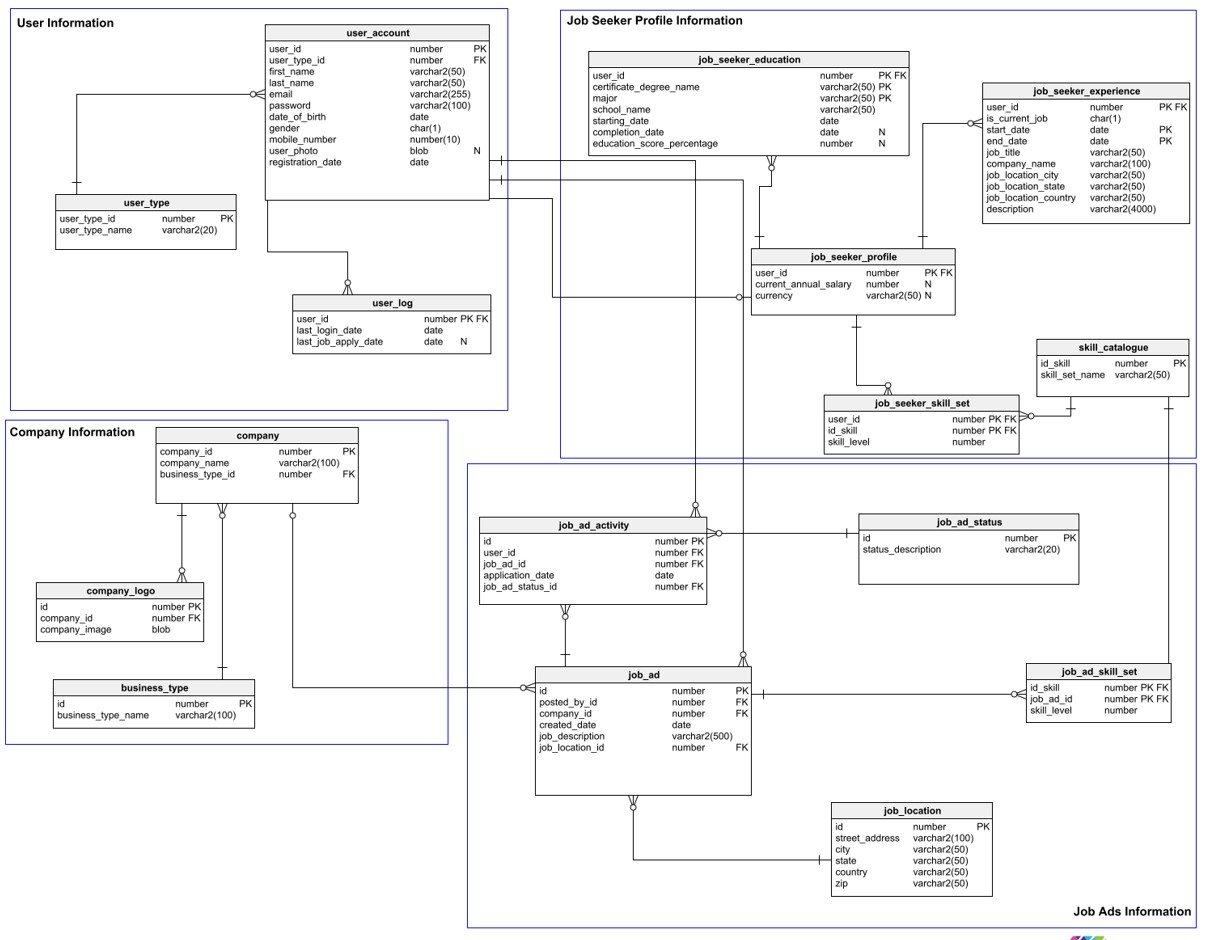
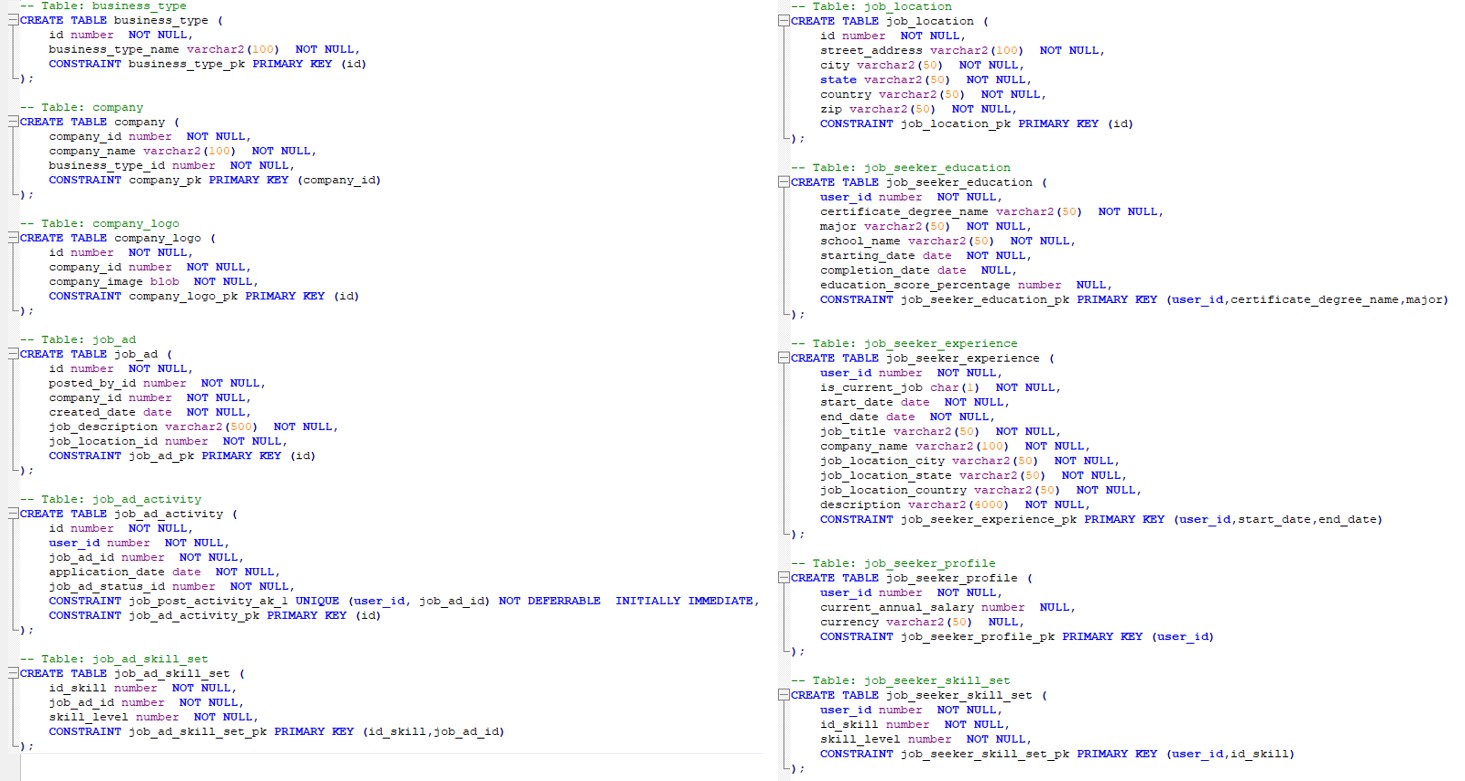
Figure 5: SQL Tables of Recruitment System Design
As a data analyst, I proposed use cases of the DBMS to optimize their hiring process, improve recruitment efficiency, and make data-driven decisions. By harnessing recruitment analytics, organizations can identify strengths, weaknesses, and areas for improvement in their talent acquisition strategies, building a skilled and diverse workforce that drives the organization’s success. I investigated GDPR regulations focused on our recruitment system. By adhering to GDPR principles, our DBMS-powered recruitment system ensures transparency, informed consent, and data subject rights for candidates throughout the hiring process. We are confident that our GDPR-compliant recruitment system will not only optimize talent acquisition but also foster trust and confidence among candidates, enhancing the organization’s reputation as a responsible data steward.
The final project closely aligned with the initial proposal, encompassing all the essential functionalities outlined in the project scope. By analysing adherence to the project scope, timeline, and milestones, and understanding user feedback, the evaluation helps provide a well-rounded understanding of the final project’s achievements and areas for growth. Ultimately, the evaluation serves as a foundation for continuous improvement and future project developments. The DBMS recruitment system efficiently managed candidate profiles, job postings, and recruitment-related data, meeting the project’s objectives effectively. Being part of a development team exposed me to the intricacies of collaborative work. I learned to leverage the diverse skills and expertise of my team members to address complex challenges in the recruitment system project. The experience fostered a sense of teamwork, enhancing my ability to work effectively in a dynamic project environment. Tutor feedback was fundamental and contributed to the project’s success.
Professionally, this module has elevated my data wrangling skills and equipped me with hands-on experience in building a DBMS recruitment system. I gained insights into data privacy regulations, such as GDPR, and their significance in managing sensitive candidate data responsibly. The project also improved my project management skills, as I learned to balance individual and work tasks while contributing to team objectives.
Personally, this journey has instilled a greater sense of resilience and adaptability. Working in a team with diverse backgrounds and time zones taught me the importance of effective communication and collaboration. The experience has translated into improved interpersonal skills, making me a more adept team player. According to Rock and Grant (2016), working with people who are different from you may challenge your brain to overcome its stale ways of thinking and sharpen its performance.
In summary, the “Deciphering Big Data” module has been instrumental in my professional and personal development. From understanding the intricacies of data extraction and cleaning techniques to collaborating in a diverse team, I have expanded my skill set and knowledge. The project’s successful implementation, adherence to GDPR, and positive feedback from peers and tutors have been affirmations of my growth as a data practitioner and a team contributor. I look forward to applying my learnings and experiences from this module to future projects and real-world data challenges. This module has been an invaluable learning experience that has shaped my understanding of data wrangling and analysis. The hands-on approach and team collaboration have enriched my skills and allowed me to grow both professionally and personally. I am grateful for the opportunity to be a part of this transformative journey, and I am confident that the knowledge and experiences gained here will continue to be assets in my future endeavours. As I move forward, I will carry the lessons learned and apply them to tackle complex data challenges, contributing positively to the field of data analytics and making meaningful contributions to the organizations I work with. The journey may have ended, but the impact it has left on me will last a lifetime.
References
Datanami. (2019) Data Pipeline Automation: The Next Step Forward in DataOps.
GDPR. “General Data Protection Regulation (GDPR).” General Data Protection Regulation (GDPR), Intersoft Consulting, 25 May 2018, gdpr-info.eu/. Accessed 30 June 2023.
IBM Intellas. (2016) Qradar and KAIF Integration Report.
Kazil, J & Jarmul, K. (2016) Data Wrangling with Python. O’Reilly. Media Inc.
Letkowski, J. (2015) Doing Database Design with MySQL. Journal of Technology Research.
McAfee, A. and Brynjolfsson, E. (2012). Big Data: The Management Revolution. [online] Harvard Business Review. Available at: https://hbr.org/2012/10/big-data-the-management-revolution [Accessed 21 Jul. 2023].
Rock, D. and Grant, H. (2016). Why Diverse Teams Are Smarter. [online] Harvard Business Review. Available at: https://hbr.org/2016/11/why-diverse-teams-are-smarter [Accessed 22 Jul. 2023].
Sarkar, T. & Roychowdhury, S. (2019) Data Wrangling with Python. 1st ed. Packt.
Williams, G. (2017) The Cybercitizen and Homeland Security. Freedom versus Fears. AICE Foundation.
Zapier (2014). An introduction to APIs / Zapier guides. [online] zapier.com. Available at: https://zapier.com/resources/guides/apis [Accessed 21 Jul. 2023].